




篱笆资讯
软件工程师求职:软件工程师面试必刷的三道系统设计问题!
我曾在Facebook和微软担任分布式系统工程师十多年,参加了数百次软件工程面试,包括编码和系统设计面试(SDI)。
系统设计面试可能令人望而生畏,没有设计大规模系统的实际经验的工程师认为SDI很吓人。除此之外,SDI与大多数技术访谈有很大不同。由于没有固定的对错答案,系统设计问题的开放性使许多受访者迷失了方向。
根据我进行系统设计面试的经验,即使是最有准备的应聘者,也总是会遇到一些问题。今天,我想帮助你确保自己在面试时不会措手不及。我将在下面的内容中讨论我提出的三个最具挑战性的系统设计问题,以及我将如何解决这些问题。
1.设计Uber
设计Uber或其他拼车服务是一个复杂的过程。在我们的两个主要主题,静态请求者(骑手)和动态接收者(驾驶员)之间,Uber应用程序上的每一次交互都必须完成大量任务。客户和驱动程序连接必须包括以下内容:
(1) 驾驶员能够经常向服务部门通知其当前位置和是否可以接单
(2) 乘客可以实时看到附近的所有司机
(3) 乘客确定目的地和时间,发起请求
(4) 当客户发起请求时,会通知附近的司机
(5) 一旦接受乘坐,驾驶员和客户必须在整个乘坐过程中查看对方的当前位置
(6) 行程完成后,该驾驶员应可以服务其他客户
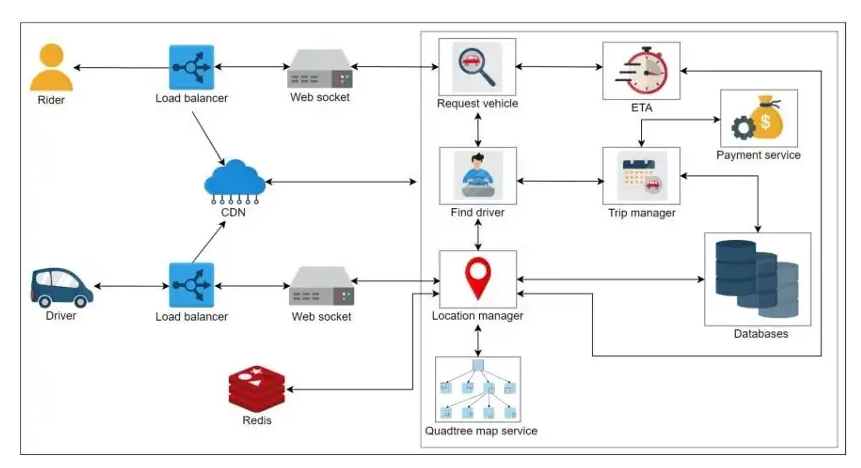
显然,这个系统有多个部分需要安装到位,以便整个操作顺利运行。为了简化方法,我建议后退一步,专注于核心问题。
我认为核心问题是系统中最难执行的部分。Uber系统最先进的部分并不是如何存储和获取收集的数据,因为这类任务是由许多大型系统完成的。
我们的核心问题是Uber的设计所独有的,是将一个(相对)静止的骑手与一个(潜在)移动的驾驶员进行匹配。平台还必须在骑行过程中告知驾驶员和骑手汽车的当前位置。
我建议先解决这个问题。如果核心问题得不到解决,系统的其余组件就无从谈起。
与Uber类似的一个设计问题是设计Yelp。我认为这是一个很好的先决条件,因为它遇到了很多与Uber相同的障碍。它们都存储大量的位置数据,并旨在基于两个实体的位置实现快速匹配结果。
这两种设计都得益于使用QuadTree数据结构将客户连接到目的地。然而,对于Uber来说,QuadTree必须适应频繁的位置更新。在大多数情况下,Yelp的系统连接两个静态点(顾客和餐厅),而Uber必须在相同的搜索时间内将移动点连接到静止点。一旦你对Yelp的设计和QuadTree感到满意,你就可以处理Uber的设计,因为它更复杂。
(附带说明:首先识别并解决“核心问题”,然后再分支到相关的系统组件,这是一种适用于任何SDI问题的技术。也就是说,我特别推荐这种方法来解决具有独特和挑战性核心问题的设计问题。把它想象成在你的盘子里吃你最不喜欢的东西,这样你就可以毫无痛苦地享受剩下的晚餐了!)
假设我们正在处理Yelp设计问题中的数据结构,Quadtree有助于将地图划分为多个部分。如果驱动程序的数量超过了某个限制,那么我们将该段拆分为四个子节点,以此来划分驱动程序。QuadTree中的每个子节点都包含无法进一步划分的段。我们可以使用相同的QuadTree段来连接驱动程序。
Yelp和Uber设计中使用的QuadTree之间最显著的区别是,我们的QuadTee没有考虑到定期升级。每当驾驶员的位置发生变化时,修改QuadTree需要更长的时间。为了确定驾驶员的新位置,我们必须首先根据驾驶员先前的位置找到合适的网格。如果新位置与当前网格不匹配,我们应该从当前网格中删除驱动程序,并将其移动到正确的网格。为了满足我们的系统要求并解决手头的问题,我们必须升级数据结构,每四秒更新一次驱动程序位置。
为了每四秒进行一次驱动程序更新,我建议从一个哈希表开始存储驱动程序的最新位置,并偶尔更新QuadTree,比如10–15秒后。我们可以大约每15秒而不是4秒更新驱动程序在QuadTree中的位置,并且我们使用每4秒更新一次的哈希表来反映驱动程序的最新位置。通过这样做,您可以在使用最少资源和时间的同时实现主要目标。
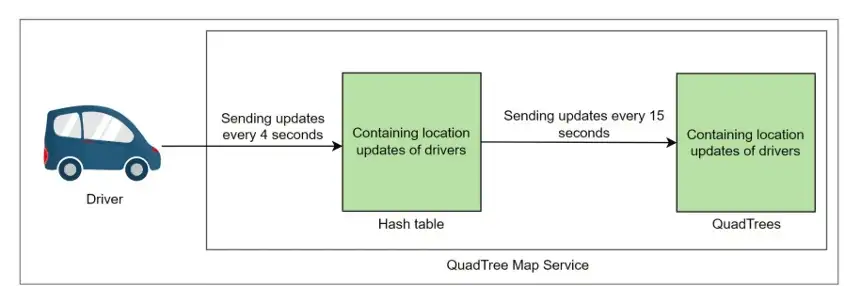
这一步只是开始。优步的设计是一个复杂而庞大的问题。在一篇文章中无法完全讲述清楚,如果你需要更加完整的指导,你可以联系篱笆老师获取更多的辅导课程。
2.推特的heavy-hitter问题
这个问题影响了许多你可能每天都会与之互动的知名公司。通常情况下,这也是经常让我的候选人混乱的问题。。
那么,heavy-hitter的问题是什么?例如,假设我们正在设计Twitter。推特系统每天都面临的一个问题是,一个拥有数百万粉丝的账号,比如贾斯汀·贝贝尔,发了一条推特,来自单个帐户的这条推文每秒可能会产生数百万条评论、浏览和点赞。随着时间的流逝,推特将继续增加其产生的流量。作为一个整体,该系统必须被构建来应对用户请求的突然激增和单个帖子的流量激增。对于Twitter、Facebook和YouTube等名人云集的公司来说,这一问题被称为heavy-hitter。
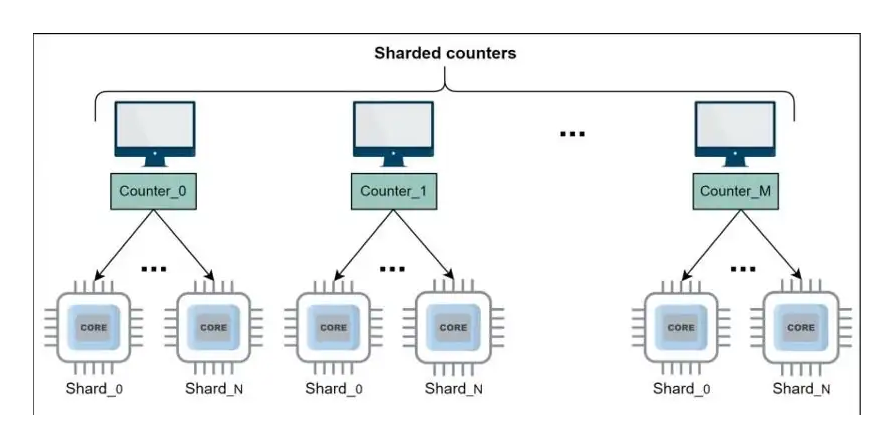
那么,你如何处理诸如heavy-hitter之类的问题?通过在一台机器上保持一个计数器来简单地计算流量并不容易。所以,我们使用碎片计数器/分片计数器,也称为分布式计数器,多个计数器负责特定数量的分片。这些碎片在不同的计算单元上并行运行。我们可以通过平衡碎片上的数百万写入请求来提高性能并限制争用。当需要可扩展计数时,碎片计数器是一个关键的设计元素。为大规模计数的可扩展性而构建,使此解决方案与我们的heavy-hitter问题完美匹配。
3.容量估算问题
容量规划不是SDI问题中最常见的问题,但它是大型FAANG系统的重要过程。首先,什么是纯容量问题?您将面临的核心问题是估计满足特定设计问题的用户需求所需的资源。例如,考虑YouTube存储每天上传的视频所需的存储空间,以及帮助将视频流传输给世界各地用户所需的服务器和带宽。
那么,我希望看到候选人如何解决这个问题?由于每个公司和系统的能力都不一样,所以对于这类问题,确实没有人能够直接解决。一个对我有很大帮助的建议是研究你面试的公司所需的带宽和容量。
例如,在YouTube的存储估计中,我们必须衡量每分钟上传到YouTube的视频总数和每个视频的长度。假设一分钟内有500小时的内容上传到YouTube。由于每个30 MB的视频长度为5分钟,因此我们需要30/5=6 MB来存储1分钟的视频。
下面的公式如下:

当然,并不是每次上传都是一样的。YouTube需要比我们计算的更多的存储空间,需要更大的灵活性。通常情况下,设计阶段的容量规划估计在现实中并不成立。这就是为什么做好灵活和持续计划的准备对于容量规划至关重要。
像上面的例子这样的计算帮助我们忽略系统的基本细节(至少在设计层面),而专注于更关键的方面。这些计算被称为“back-of-the-envelope calculations(后台计算)”,其本身并不代表实际容量。此外,我们还必须做出一些基本假设,这些假设将成为我们容量计算的基础。
例如,我们可以估计每个服务器的存储容量,然后估计存储所有视频所需的存储服务器的数量。我们还可以假设视频的块/段的复制数量,1KB数据从一个数据中心传输到另一个数据的延迟时间,等等。
容量评估问题应在系统设计面试准备中进行更多讨论。在我看来,因为设计并不总是转移到现实中,所以容量估计是现代大规模系统设计中最关键和最具挑战性的方面之一。
系统设计是当今世界的重要组成部分,我总是喜欢看到每年有更多的人进入这个领域。无论你是谁,系统设计面试都很棘手。这就是为什么我想分享尽可能多的专业知识,以解决我看到的导致候选人困惑的问题。
既然你已经意识到这些关键的问题,请确保在真正面试之前练习这些问题! 祝你好运!



 直连行业大牛导师,1v1模拟面试与求职指导
直连行业大牛导师,1v1模拟面试与求职指导

 实战与求职精品课程
实战与求职精品课程
 2000+名企面试真题
2000+名企面试真题











