A collection of machine learning algorithms: from Bayes to deep learning and their respective advantages and disadvantages(part two)
Deep Learning
Deep learning is the latest branch of artificial neural networks, which benefits from the rapid development of contemporary hardware.
The current direction of many researchers is focused on building larger and more complex neural networks, and many approaches are currently focusing on semi-supervised learning problems in which the large data sets used for training contain only few tokens. Examples:
• Deep Boltzmann Machine,DBM • Deep Belief Networks(DBN) • Convolutional Neural Network(CNN) • Stacked Auto-Encoders
Advantages/disadvantages: see Neural Networks Support Vector Machines
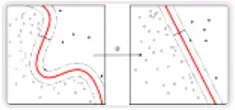
Given a set of training cases, each of which belongs to one of two categories, a Support Vector Machine (SVM) training algorithm can classify a new case when it is being input to one of the two categories, making itself a non-probability binary linear classifier.
The SVM model represents training examples as points in space, which are mapped into a graph separated by a clear, widest possible interval to distinguish between the two categories.
Subsequently, new examples are mapped into the same space to predict the category it belongs to based on which side of the interval they fall on.
Advantages:
Excellent performance on non-linear separable problems
Disadvantages:
• Very difficult to train
• Very difficult to interpret
Dimensionality Reduction Algorithms Similar to the clustering approach, the pursuit of dimensionality reduction and take advantage of the inherent structure of the data with the aim of using less information to summarize or describing the data.
The algorithm can be used for visualizing high-dimensional data or simplifying the data that can then be used for supervised learning. Many of these methods can be adapted for the use of classification and regression.
• There is no need to make assumptions on the data
Disadvantages:
• Difficult to handle non-linear data
• Difficult to understand the meaning of the results
Clustering Algorithms Clustering algorithms are used to classify a group of targets, where targets that belong to the same group (i.e., a class, cluster) are classified in a group that is more similar to each other than to other groups of targets (in some sense).
Example :
• K-Mean (k-Means)
• k-Medians algorithm
• Expectation Maximi closure ation (EM)
• Maximum Expectation Algorithm (EM)
• Hierarchical Clustering (HCC)
Advantages:
• Makes sense of the data
Disadvantages:
• Results are difficult to interpret, and for unusual data sets, results may be useless.
Instance-based Algorithms Example-based algorithms (sometimes called memory-based learning) are algorithms that learn in this way, not by explicit summarization, but by comparing new problem examples with examples that have been seen during training, and that are in the memorizer.
It is called an instance-based algorithm because it constructs the hypothesis directly from the training instances. This means that the complexity of the hypothesis can change as the data grows: in the worst case, the hypothesis is a list of training items and the computation complexity of classifying a single new instance is O(n)
Examples:
k-Nearest Neighbor (kNN)
Learning Vector Quantization (LVQ)
Self-Organizing Map (SOM)
Locally Weighted Learning (LWL)
Advantages:
• Simple algorithm, results are easy to interpret
Disadvantages:
• Very high memory usage
• High computational expense
• Impossible to use for high dimensional feature space
Bayesian Algorithms Bayesian method are methods that explicitly apply Bayes' theorem to solve problems such as classification and regression. Examples: • Naive Bayes • Gaussian Naive Bayes • Multinomial Naive Bayes • Averaged One-Dependence Estimators (AODE) • Bayesian Belief Network (BBN)
• Bayesian Network (BN)
Advantages:
Fast, easy to train, gives the resources they need to deliver good performance
Disadvantages:
• Problem occurs if input variables are relevant
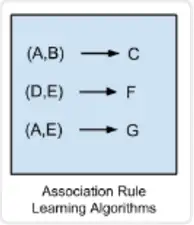
Association Rule Learning Algorithms
The association rule learning method is able to extract the best explanation of the relationship between the variables in the data. For example, if the rule {onions, potatoes} => {burgers} exists in the sales data of a supermarket, it means that when a customer buys both onions and potatoes, he is likely to also buy hamburger meat.
Examples:
• Apriori algorithm • Eclat algorithm • FP-growth
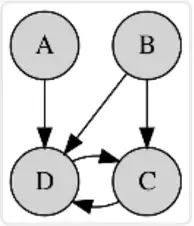
Graphical Models Examples:
• Bayesian network
• Markov random field
• Chain Graphs
• Ancestral graph
Advantages:
Clear model, can be understood visually
Disadvantages:
Determining the topology of its dependencies is difficult and sometimes vague








 直连行业大牛导师,1v1模拟面试与求职指导
直连行业大牛导师,1v1模拟面试与求职指导

 实战与求职精品课程
实战与求职精品课程
 2000+名企面试真题
2000+名企面试真题











