




篱笆资讯
TikTok面经:速来!TikTok机器学习工程师最新面试题+答案分享,帮你高效准备面试
Round 1: algorithm and coding
1、Find the indexes of max values in a given array.
(example)
I have this:
var arr = [0, 21, 22, 7];
What's the best way to return the index of the highest value into another variable?
Answer:
function indexOfMax(arr) {
if (arr.length === 0) {
return -1;
}
var max = arr[0];
var maxIndex = 0;
for (var i = 1; i < arr.length; i++) {
if (arr[i] > max) {
maxIndex = i;
max = arr[i];
}
}
return maxIndex;
}
2、Followup: if there are multiple maximum values, return either one with equal probability.
(example)
Program to return the index of the maximum number in the array [ To Note : the array may or may not contain multiple copies of maximum number ] such that each index ( which contains the maximum numbers ) have the probability of 1/no of max numbers to be returned.
Examples:
[-1 3 2 3 3], each of positions [1,3,4] have the probability 1/3 to be returned (the three 3s)
[ 2 4 6 6 3 1 6 6 ], each of [2,3,6,7] have the probability of 1/4 to be returned (corresponding to the position of the 6s).
Answer:
int find_maxIndex(vector<int> a){
int count = 1;
int maxElement = a[0];
for(int i = 1; i < a.size(); i++){
if(a[i] == maxElement){
count ++;
} else if(a[i] > maxElement){
count = 1;
maxElement = a[i];
}
}
int occurrence = rand() % count + 1;
int occur = 0;
for(int i = 0; i < a.size(); i++){
if(a[i] == maxElement){
occur++;
if(occur == occurrence) return i;
}
}
}
Round 2: Machine Learning concept and modeling
1、How do you train and test an ML system on streaming data and make sure the model doesn’t overfit;
(example)
How do you ensure you’re not overfitting with a model?
Answer: This is a simple restatement of a fundamental problem in machine learning: the possibility of overfitting training data and carrying the noise of that data through to the test set, thereby providing inaccurate generalizations.
There are three main methods to avoid overfitting:
Keep the model simpler: reduce variance by taking into account fewer variables and parameters, thereby removing some of the noise in the training data.
Use cross-validation techniques such as k-folds cross-validation.
Use regularization techniques such as LASSO that penalize certain model parameters if they’re likely to cause overfitting.
2、Ideas of concept drift and data drift.
(example)
What’s the difference between concept drift and data drift ?
The performance of a machine learning model degrades over time, absent intervention. This is why model monitoring is an important component of a production ML system. When a machine learning model’s predictions start to underperform, there can be several culprits.
After ruling out any data quality issues, the two usual suspects are data drift and concept drift. It’s important to understand the difference between them, because they require different approaches.
In data drift, the input has changed. The trained model is no longer relevant on the new data.
In concept drift the data distribution hasn't changed. Rather, the interaction between inputs and outputs is different than before. ֵIt practically means that what we are trying to predict has changed. A classic example is spam detection: over time, spammers try new tactics, so the spam filters need to be retrained to react to these new patterns.
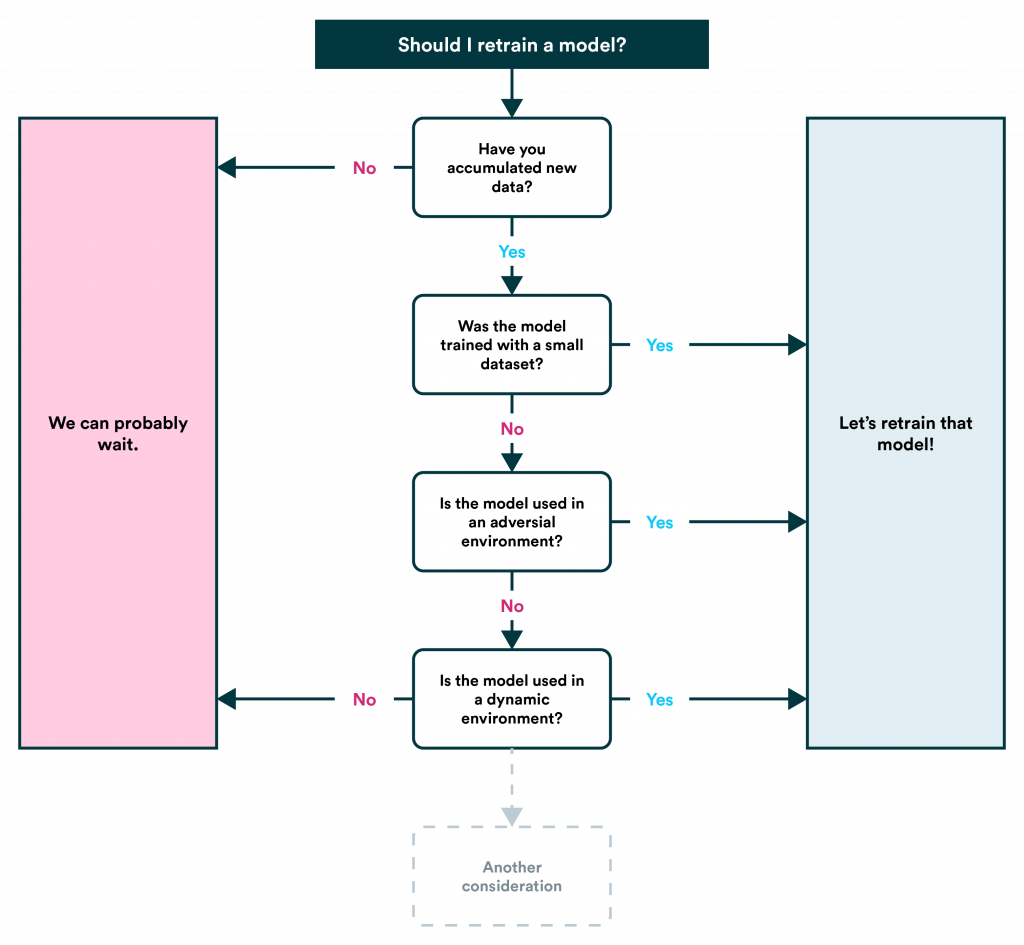
3、How do we determine it’s time to retrain the model and decide how often we need to retrain the model.
(example)
When to Your Machine Learning Model
(1)What Causes Model Staleness?
Perhaps the primary cause for model staleness and performance degradation is concept drift (known also as model drift). One of the core assumptions in ML is that the distribution of the training data is the same as that of the test data. However, changes in the world such as shifting markets and user behavior as well as seasonal changes can greatly affect the essence of the phenomenon we are trying to model, deeming our existing ML model irrelevant. Additional common causes include changes in the format of the data such as features that become available, or features that have stopped being available.
(2)Triggers for Retraining
Which events should trigger a retraining of your model? For one, if a significant amount of additional data becomes available, especially if the original training dataset wasn’t very large – retraining will boost your model’s performance significantly.
Another thing to notice is whether there are any schema changes in the data such as renaming of a column or introduction of a new feature. These changes can have a dramatic effect on the model’s performance. In some cases, this may be solved by a simple processing step to translate between formats, but in other cases may require a full retraining procedure.
Furthermore, if your model’s performance is degrading, it is likely time to retrain your model. This process can even be automated by using triggers that detect when performance goes under some threshold, or using anomaly detection techniques. However, it is not always easy to assess the model’s performance in real time as ground truth labels may not be available for a while, and thus you may need to estimate the correct time to retrain. This could be done using backtesting, by dividing the existing training data into “past” and “future” examples, and measuring the corresponding drift. Additionally, significant data drift is likely to reflect concept drift, and this can be measured even when labels aren’t available.
Another point to consider, is that dramatic trends and events in the actual world may indicate that your model will stop performing as expected. For example, the spread of the coronavirus pandemic hit industries around the world, affecting many ML models in production. In April of 2020, the top 10 search terms on Amazon.com included: toilet paper, face mask, and hand sanitizer – items which were significantly less popular before the pandemic.
Finally, you should ask yourself whether your model might be subject to a feedback loop, where the model’s predictions may actively cause performance degradation over time, or whether your model may be subject to adversarial attacks, where users are actively trying to generate a specific outcome from your model. If one of these issues apply in your case, your are likely to need to retrain your models more frequently.
Following is a useful chart by Henrik Skogström that summarizes the cases in which you may need to retrain your ML model:
Round 3: leadership and behavioral questions
1、Why leave your current job, and why do you want to join TikTok?
2、Salary expectation, logistics such as Visa sponsorship, start date, relocation.



 直连行业大牛导师,1v1模拟面试与求职指导
直连行业大牛导师,1v1模拟面试与求职指导

 实战与求职精品课程
实战与求职精品课程
 2000+名企面试真题
2000+名企面试真题











