




篱笆资讯
北美求职:数据科学与数据挖掘的主要区别(下)
什么是数据挖掘?
术语数据挖掘出现在1990年的数据库社区中。零售公司和金融界使用数据挖掘来分析数据和识别趋势,以增加客户群,并预测股票价格、利率和客户需求的波动。
数据挖掘是在大型数据集中识别模式的过程。它涉及数据库系统、统计和机器学习交叉的方法。计算机科学和统计学的这个跨学科子领域的总体目标是通过使用复杂的数学算法从大型数据集或数据库中提取信息,并将它们转换为可理解的结构以供进一步使用。
数据挖掘通过仔细提取、审查和处理原始数据来帮助获得见解,以发现对企业有价值的模式和相关性。数据挖掘过程包括不同类型的服务,例如:
- 网络挖掘
- 文本挖掘
- 音频挖掘
- 视频挖掘
- 社交网络数据挖掘
- 图形数据挖掘
数据挖掘也称为数据中的知识发现(KDD),是在简单或高级软件的帮助下执行的。数据挖掘涉及以下步骤:
(1)业务理解:它涉及介绍和理解业务的目标和工作,以及了解有助于实现业务目标的重要因素。
(2)数据理解:它执行数据收集和数据积累。数据根据源数据、其位置、实现方式以及是否出现任何问题列出。然后对数据进行可视化并检查其完整性。
(3)数据准备:它涉及选择有用的数据、清理数据、从中构造属性以及从多个数据库集成数据。
(4)建模:它涉及选择数据挖掘技术,生成测试设计以评估所选模型,从数据集构建模型,以及与专家一起评估模型以了解结果。
(5)评估:它通过基于实际应用程序进行测试来确定生成的模型满足业务需求的程度。
(6)部署:它创建一个部署计划,并形成一个策略,通过维护和监视来检查数据挖掘模型的有用性。
数据挖掘的应用
数据挖掘的一些应用是:
(1)市场分析
(2)财务分析
(3)高等教育
(4)欺诈检测
数据挖掘与数据科学
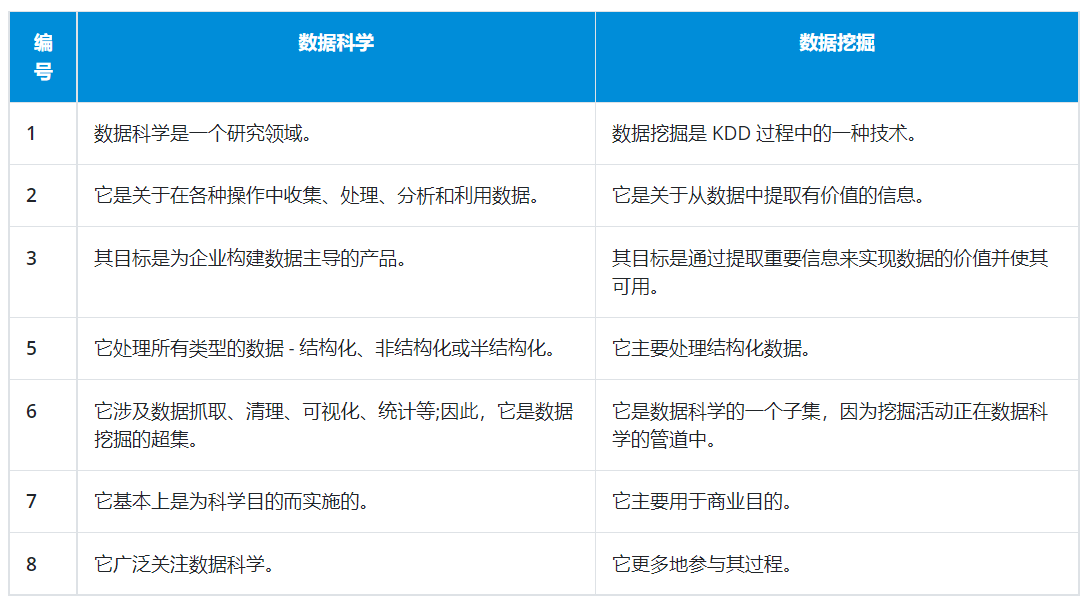
虽然数据科学是一个广泛的领域,涉及捕获数据、分析数据并从中获得可操作的见解,但数据挖掘主要涉及在数据集中查找有用的信息并利用它来识别隐藏的模式。
数据科学和数据挖掘之间的另一个很大区别是,前者是一个由统计学、数据可视化、社会科学、自然语言处理(NLP)和数据挖掘组成的多学科领域,这意味着数据挖掘是数据科学的一个子集。
在某种程度上,数据科学家可以被认为是人工智能(AI)研究人员,机器学习工程师,深度学习工程师和数据分析师的组合。另一方面,数据挖掘专业人员不一定能执行所有这些角色,而这些角色可以由数据科学家执行。
另一个显着的区别在于使用的数据类型。数据科学主要处理所有类型的数据,例如结构化、非结构化和半结构化。但是,数据挖掘主要处理结构化数据。
在考虑工作性质时,数据科学和数据挖掘之间还有另一个区别。发现模式并对其进行分析是数据挖掘的关键组成部分。数据科学涉及相同的内容,但它也涉及通过使用各种工具和技术利用当前和历史数据来预测未来事件。
数据科学侧重于数据科学,而数据挖掘主要关注检测异常和不一致以及预测结果的过程。
无论是数据科学还是数据挖掘,在处理呈指数级增长的数据量时,两者都在帮助企业识别机会和做出合理决策方面发挥着至关重要的作用。因此,虽然数据科学和数据挖掘的目标在某种程度上是相似的,即获得帮助企业更好表现和发展的见解,但关键区别在于实施的工具和技术、工作性质以及履行各自职责所涉及的阶段。


 直连行业大牛导师,1v1模拟面试与求职指导
直连行业大牛导师,1v1模拟面试与求职指导

 实战与求职精品课程
实战与求职精品课程
 2000+名企面试真题
2000+名企面试真题











